
Relation Extraction
Published:
Table of contents
During the summer vacation, I worked on the extraction of diseases and its symptoms at Synyi (A medical AI startup). Since I hadn’t solved the problem before, I did a literature review to learn different methods used to solve the Relation Extraction problem.
On 10/11/2017, I attended a seminar hosted at ADAPT, and one of master students (Yangyang) gave a talk about Relation Extraction (RE). It reminded me of the literature review I did one month ago, then I decided to write this blog and I believed that it can give an overview of the development of RE methods.
Chapter 0: Introduction
Relation Extraction (RE) is a sub-task of Information Extraction (IE). The other two are Named Entity Recognition (NER) and Event Extraction.
The purpose of RE is to solve the problem of machine reading. After constructing structured data, which machine can utilize, from unstructured text, the machine can “understand” the text.

Here is an example of RE:
CHICAGO (AP) — Citing high fuel prices, United Airlines said Friday it has increased fares by $6 per round trip on flights to some cities also served by lower-cost carriers. American Airlines, a unit of AMR, immediately matched the move, spokesman Tim Wagner said. United, a unit of UAL, said the increase took effect Thursday night and applies to most routes where it competes against discount carriers, such as Chicago to Dallas and Atlanta and Denver to San Francisco, Los Angeles and New York.
There are many relations that could be extracted from the text:
| Subject | Relation | Object |
|---|---|---|
| American Airlines | subsidiary | AMR |
| Tim Wagner | employee | American Airlines |
| United Airlines | subsidiary | UAL |
| ... | ... | ... |
In this blog, I’ll introduce different methods researchers proposed to solve the problem. The methods will be separated into 2 categories, traditional machine learning approach and recently risen neural network approach.
I make the assumption that readers are familiar with basic machine learning and natural language peocessing (NLP) concepts, such as classifier, POS tag, corpus, to name just a few. I’ll focus on the ideas that are used to solve the problem and will not go deep into detail such as what is a model or how to train a model.
Chapter 1: Machine Learning
Researchers started to explore the field at 1990’s. They come up with different ideas to get better performance, to solve under more and more complicated circumstances.
Rule based
Rule-based approach is straightforward (may not be considered as a machine learning method, I put it here because it is far more different with neural network approaches), it assumes that the pattern (“pattern” and “rule” are the same in my discussion) appears in one instance will appear again and again for the same relation type. Thus we can extract hundreds or thousands of relations pairs with a single pattern from the huge corpus, sometimes unlimited data from the Internet.
Rule-based approach utilizes traditional NLP tools, such as word segmentation (in Chinese), NER , POS tagger, dependency parser, etc.
In 1992, for instance, Hearst et al.[1] proposed a rule-based way to extract hyponymy. Some of the rules they used is listed below.
| Pattern | Example | Hyponym |
|---|---|---|
| Y, such as {X,}* {or | and} X | ... works by such authors as Herrick,Goldsmith, and Shakespeare. | ("author", "Herrick") ... |
| X {,X}* {,} or other Y | Bruises, wounds, broken bones or other injuries ... | ("injury", "bruise") ... |
| X {, X} * {,} and other Y | ... temples, treasuries, and other important civic buildings. | ("civic building", "temple") ... |
| Y {,} including {X,}* {or | and} X | All common-law countries, including Canada and England ... | ("common-law country", "Canada") |
| ... | ... | ... |
There are several shortcomings of the rule-based method.
- Requires hand-built patterns for each relation
- hard to write and maintain
- almost unlimited patterns
- domain-dependent
- The accuracy is not satisfying:
- Hearst (the system above): 66% accuracy.
Bootstrapping
Now you find that it is so boring and time-consuming to look for these patterns in corpus. Fortunately, a method called “bootstrapping” is proposed to relief your hands.
When you have a lot of unlabeled data (E.g. from the Internet) and some seeds of relation-pairs or patterns that works well, you can use the seeds to find more sentences that contains the relation-pair and generate more patterns that is likely to express the same relation. So the model will learn patterns and use patterns to get more instances and patterns. After iterations, the outcome is tremendous.
Bootstrapping can be considered as a semi-supervised approach. Image below is a clear representation.
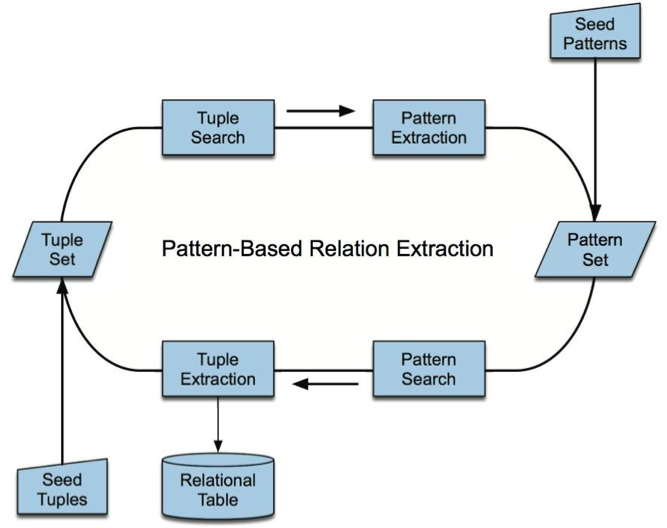
For example, Brin[2] used bootstrapping to extract (author, book) pairs from the Internet.
Started with only 5 relation-pairs:
| Author | Book |
|---|---|
| Isaac Asimov | The Robots of Dawn |
| David Brin | Startide Rising |
| James Gleick | Chaos: Making a New Science |
| Charles Dickens | Great Expectations |
| Wiliam Shakespeare | The Comedy of Errors |
After several iterations, over 15,000 relation-pairs were found with an accuracy of 95%.
It seems that the bootstrapping method is promising, however, it is not the case. The high accuracy of the above experiment doesn’t consist with other relation types. Take (President, Country) as an example, we may choose (Obama, America) as a seed. It is obvious that it will generate many noisy patterns.
Obama returned to America after visiting Peking, China.
Such noise would be amplified during iterations and reduce the accuracy.
So there are some problems of bootstrapping:
- Requires seeds for each relation type
- result is sensitive to the seeds
- Semantic drift at each iteration
- precision not high
- No probabilistic interpretation
Supervised method
Consider the situation that we have gathered plenty of labeled data, the relation extraction task can thus be treated as a classification task. The input is a sentence with two entities (binary relation), the output can be either a boolean value (whether there is a certain relation between the two entities) or a relation type.
The things we need to do are:
- Collect labeled data
- Define output label
- Define features
- Choose a classifier
- Train the model
We can use as many as features as we want to improve the performance of the model. Practically, NLP tools are frequently used to extract features.
- bags of words; bi-gram before/after entities; distance between entities
- phrase chunk path; bags of chunk heads
- dependency-tree path; tree distance between entities
- …
Also, classifiers are free to choose:
- Support Vector Machine
- Logistic Regression
- Naive Bayes
- …
To summarize:
- Supervised approach can achieve high accuracy
- if we have access to lots of hand-labeled training data
- Limitation is the same significant
- Hand labeling is expensive
- Feature engineering is domain-dependent
Distant supervised method
As discussed in last section, supervised method works well when lots of labeled data is available. But labeling so much data is a great burden for researchers. With the ambition to utilize the almost unlimited unlabeled data, researchers came up with a method that can generate vast, though noisy, training data, named distant supervision (Mintz et al.)[3].
The assumption is:
If two entities participate in a relation, any sentence containing those two entities is likely to express that relation.
With the help of high quality relation databases (such as Freebase), we can annotate tremendous training data with the unlabeled text.
You may consider that it is similar to bootstrapping. Well, they both attempt to take advantage of unlabeled data. However, bootstrapping simply uses pattern to match the object, while distant supervision utilizes rich feature engineering and classifier to find a probabilistic interpretation of the RE task.
Distant supervised method has many advantages:
- Leverage rich, reliable hand-created knowledge (the databases)
- Leverage unlimited unlabeled text data
- Not sensitive to corpus (collecting training data step)
Multi-instance learning
The assumption made by distant supervision is strong so that the training data is noisy. In 2010, Riedel et al.[7] relaxed the distant supervision assumption to:
If two entities participate in a relation, at least one sentence that mentions these two entities might express that relation.
So the task could be modeled as a multi-instance learning problem, thus exploiting the large training data created by distant supervision while being robust to the noise.
A multi-instance learning problem is a form of supervised learning where a label is given to a bag of instances instead of a single instance. In the context of RE, every entity-pair defines a bag consists of all sentences that mention the entity-pair. Rather than giving label to every sentence, a label is instead given to each bag of the relation entity.
Multi-instance Multi-labeling (MIML)
The multi-instance learning assumes that one bag of instances only has one relation type, which is not the case in reality. It is trivial that one entity-pair can have more than one relation.
In 2012, Surdeanu et al.[9]proposed a MIML method to solve the shortcoming.
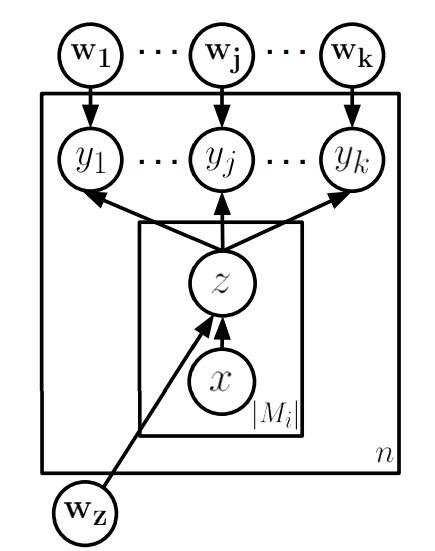
This method is more complicated than the previous ones, it uses multi-class classifier and several binary classifiers. I recommend you to read the paper on your own.
Chapter 2: Neural Network Approach
Since 2014, researchers started to use neural network models to solve the task. The main idea is the same, considering RE task as a classification problem. Experiments show that neural network outperforms many state-of-art machine learning methods. In this chapter, I’ll introduce several NN architectures proposed to solve the RE task, each contains ideas that contribute to the high performance.
Recently another approach is proposed, treating RE as a sequence tagging problem (sometimes jointly extracted with entities), I’ll discuss this approach later in the blog.
Simple NN model
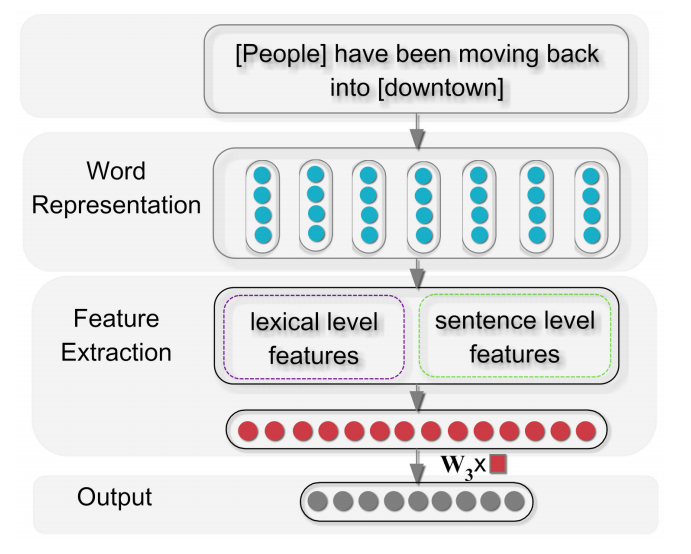
The simplest NN model uses word embedding[5] as input, extract features to have a static length representation of the sentence, and then apply a linear layer to do classification.
CNN with max-pooling
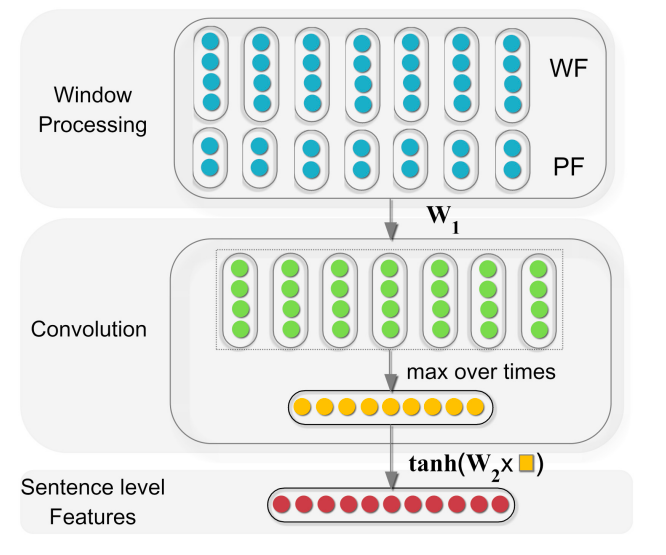
You may be confused that I doesn’t explain the feature extraction layer in Figure 4. The truth is that I skip it deliberately because I’m willing to introduce it in this section.
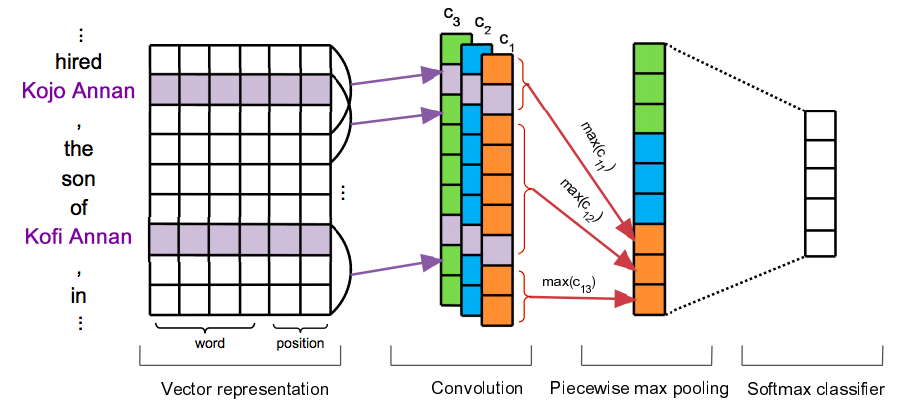
As you can see in Figure 5, Zeng et al.[4] use a convolution layer to get fixed-length feature at sentence-level.
Note that in the first layer, the WF stands for Word Feature (word embedding), and the PF stands for Position Feature which encodes the word’s distance to the entities.
CNN with multi-sized kernels
In 2015, Nguyen et al.[6] proposed to use multi-sized kernels to encode the sentence-level information with n-gram information. It is intuitive that different size of kernels are able to encode different n-gram information.
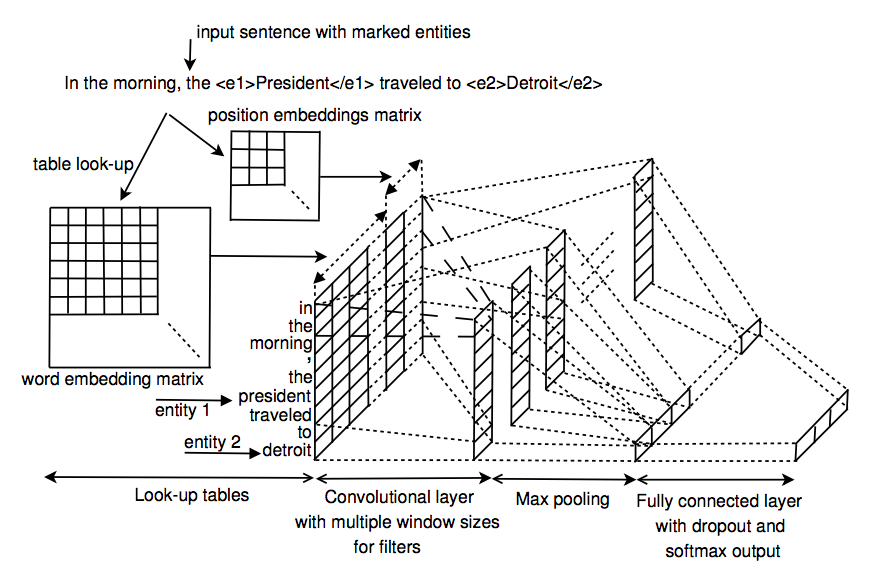
Piecewise CNN with multi-instance learning
Recall the previously discussed multi-instance learning method, in 2015, Zeng et al.[8] proposed a neural network approach to exploit the relaxed distant supervision assumption.
Given all(\(T\)) training bags \((M_{i}, y_i)\), \(q_i\) denotes the number of sentences in the \(i^{th}\) bag, the object function is defined using cross-entropy at bag level:
\[J(\theta) = \sum_{i=1}^{T} \log p(y_i\ |\ {M{_i}{^{j^\ast}}}, \theta)\]where \(j^\ast\) is constrained as:
\[j^\ast = \arg \max_{j} p(y_i\ |\ {M{_i}{^j}}, \theta), 1 \le j \le q_i\]From the equation we can find that Zeng et al.[8] give a label to a bag according to the most confident instance.
Another contribution in Zeng et al.[8] is the piecewise CNN (PCNN). As report in the paper, the author claims that the max-pooling layer drastically reduces the size of the hidden layer and is also not sufficient to capture the structure between the entities in the sentence. This can be avoided by applying max-pooling in different segments of the sentence instead of the whole sentence. In RE task, a sentence can be naturally divided into 3 segments, before first entity, between 2 entities and after the second entity.
Attention over instances
The shortcoming of Zeng et al.[8] is that it only uses that most confident instance from the bag. To overcome it, Lin et al.[10] applies attention mechanism over all the instances in the bag for the multi-instance problem.
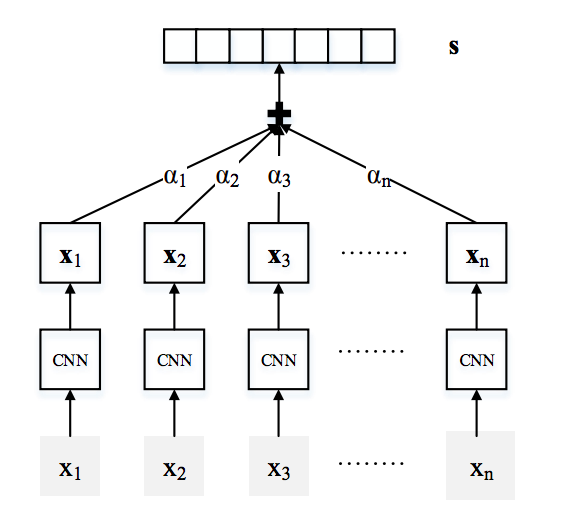
As shown in Figure 8, each sentence \(x_i\) in a bag is encoded into a distributed representation through PCNN (Zeng et al.[8]) or CNN. Then the feature vector representing the \(i^{th}\) bag \(s_i\) is given as,
\[s_i = \sum_{j=1}^{q^i} \alpha_j x_i^j\]Note that the attention parameter \(\alpha_j\) is officially defined in Lin et al.[10]. The equation above is a simplified version which express the same idea.
Multi-instance Multi-labeling CNN
Like the MIML model proposed Surdeanu et al.[9], Jiang et al.[11] proposed a MIML approach with CNN architecture, named MIMLCNN.
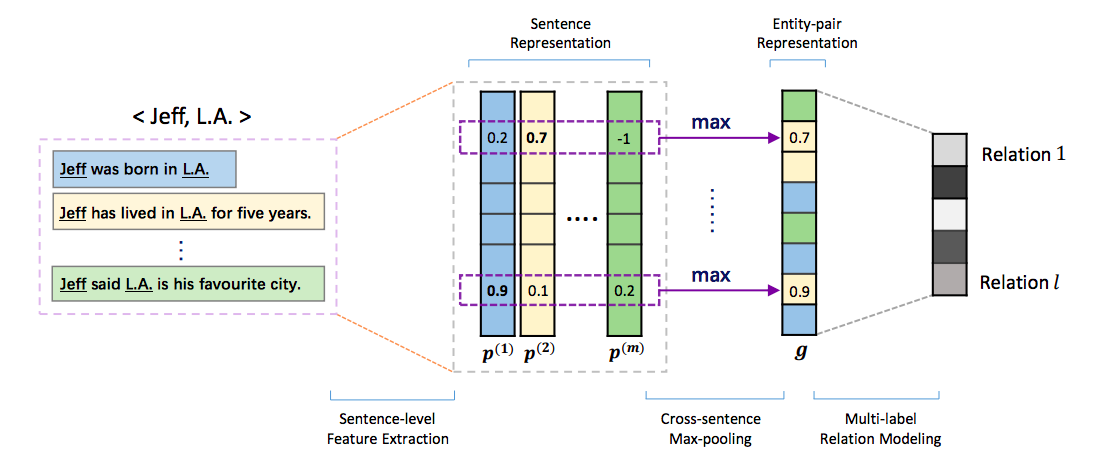
The model uses a cross-sentence max-pooling to encode the bag information. In the last layer the author applies \(Sigmoid\) so that each element of the output vector can be considered as a probability of the corresponding relation type given the instance bag.
Sequence Tagging Approach
In many situation, the performance of pre-trained NER will influence the downstream task, relation extraction, a lot. So researchers began to have a try on joint extraction of entities and relations.
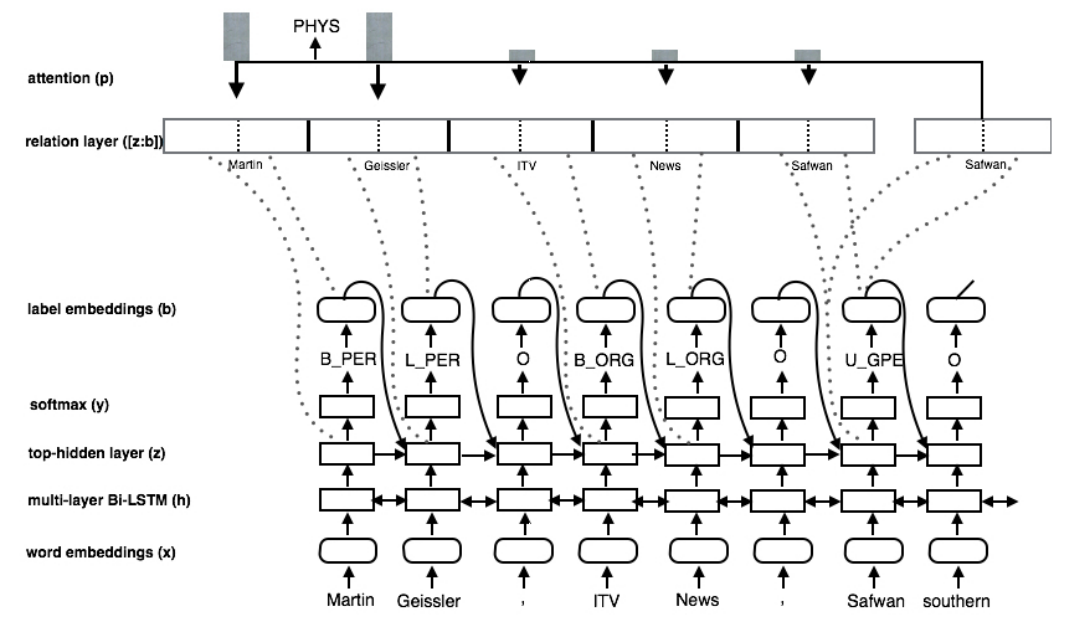
In Katiyar et al.[12], the joint extraction is accomplished in two steps, first NER, then RE. As shwon in Figure 10.
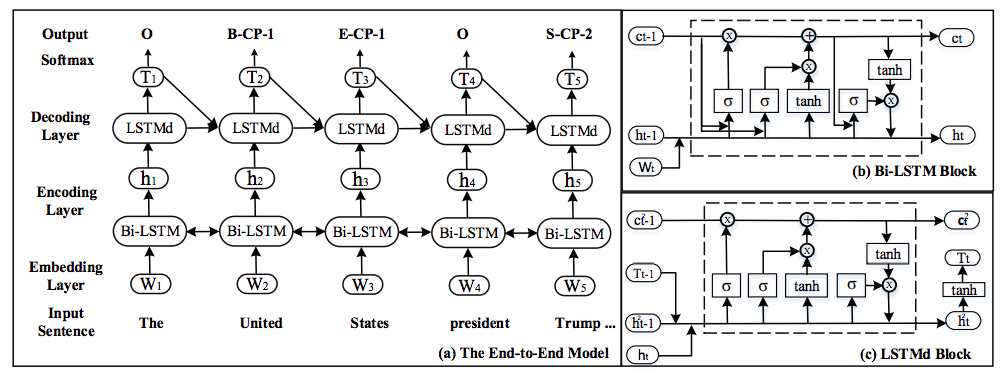
In Zheng et al.[13], the author proposed a novel tagging scheme to extract named entities and relations in one step. As shown in Figure 11, with the new annotating scheme, the joint extraction problem can be treated as a simple sequence tagging problem.

Recommended Reading
- Nandakumar, Pushpak Bhattacharyya. “Relation Extraction.” (2016).
- Kumar, Shantanu. “A Survey of Deep Learning Methods for Relation Extraction.” arXiv preprint arXiv:1705.03645 (2017).
Reference
- Hearst, Marti A. “Automatic acquisition of hyponyms from large text corpora.” Proceedings of the 14th conference on Computational linguistics-Volume 2. Association for Computational Linguistics, 1992.
- Brin, Sergey. “Extracting patterns and relations from the world wide web.” International Workshop on The World Wide Web and Databases. Springer, Berlin, Heidelberg, 1998.
- Mintz, Mike, et al. “Distant supervision for relation extraction without labeled data.” Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2-Volume 2. Association for Computational Linguistics, 2009.
- Zeng, Daojian, et al. “Relation Classification via Convolutional Deep Neural Network.” COLING. 2014.
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119).
- Nguyen, T. H., & Grishman, R. (2015, June). Relation Extraction: Perspective from Convolutional Neural Networks. In VS@ HLT-NAACL (pp. 39-48).
- Riedel, Sebastian, Limin Yao, and Andrew McCallum. “Modeling relations and their mentions without labeled text.” Machine learning and knowledge discovery in databases (2010): 148-163.
- Zeng, D., Liu, K., Chen, Y., & Zhao, J. (2015, September). Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. In Emnlp (pp. 1753-1762).
- Surdeanu, M., Tibshirani, J., Nallapati, R., & Manning, C. D. (2012, July). Multi-instance multi-label learning for relation extraction. In Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning (pp. 455-465). Association for Computational Linguistics.
- Lin, Yankai, et al. “Neural Relation Extraction with Selective Attention over Instances.” ACL (1). 2016.
- Jiang, Xiaotian, et al. “Relation Extraction with Multi-instance Multi-label Convolutional Neural Networks.” COLING. 2016.
- Katiyar, Arzoo, and Claire Cardie. “Going out on a limb: Joint Extraction of Entity Mentions and Relations without Dependency Trees.” Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vol. 1. 2017.
- Zheng, Suncong, et al. “Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme.” arXiv preprint arXiv:1706.05075 (2017).